
Visual Sentiment Analysis: A Need for Context
Previously, we gave our readers a glance at visual sentiment analysis in an earlier blog post. The goal of the task was seeking the sentiment expressed in images, formulated as an image classification problem. In the first attempt, we gave an answer to the question of whether the pictures reflected the sentiment of the photographers.
In our investigation, we focus on images from online reviews whereby the sentiment is arguably subjective to the reviewers with their personal experiences. One question then arises:
Do different customers express the same sentiment to the same food?
Taking a closer look at the data, we discover some interesting disagreements among our “photographers”. With an example between two visually similar pictures of tacos from the same restaurant, there is a polarity in term of sentiment given by two different reviewers.

Interestingly, the sentiment tends to be expressed in the form of a mixture between crowd agreements and personal preferences. The former is well captured by the presented CNN model but the later has not been considered.
What should be the right way to detect the sentiment is this scenario?
For this particular setting where the images are coming from online reviews, the problem shares some similarities with the notion of “visual-aware recommender systems” that seeks to capture user preferences from interactions with visually-featured items. Though we work with online reviews, the problem of visual sentiment analysis does not always come with the notion of preferences. For generality, we frame the problem as visual sentiment analysis with multiple contexts, where users and items are contexts in this scenario. Contexts can be as specific as each user or as general as sources of data where the images come from.
Our hypothesis is that sentiment is not purely a function of the image features alone but rather the image-context combination. We are then left with another question which is how to inject the notion of contexts into the model. We tailor the CNN originally designed to learn a sentiment detector from images, making it context-aware by having a subset of parameters influenced by each context.
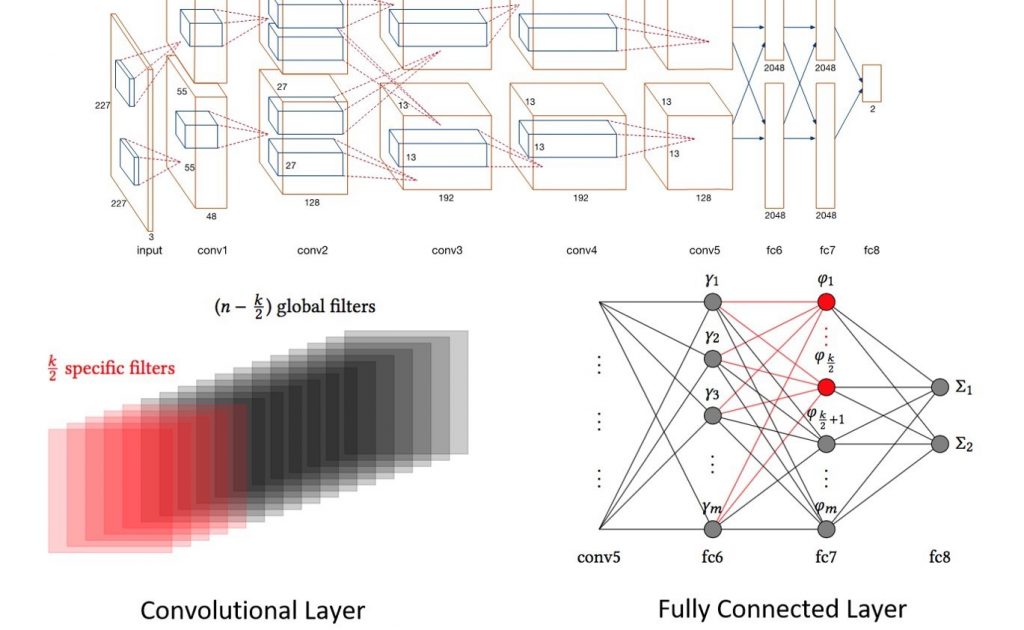
There are two basic components, convolutional layers and fully-connected layers, in our CNN architecture leading to two ways of introducing the contexts. For a convolutional layer with n filters/kernels, we make k out of n context-specific; alternatively, k out of n neurons for a fully-connected layer. From the practical point of view, a filter of a convolutional layer is equivalent to a neuron of a fully-connected layer. To learn with new networks, we have to optimize the parameters under the online learning setting. The interested readers may find details of the training in our paper.
In addition to improvements in quantitative results, we would like to lend some intuitions of how the contexts influence our sentiment detector. We first look at the images assigned the highest probability of positive sentiment by the base CNN without the involvement of contexts. One of the image clusters is about a small group of people celebrating something with cake and candle, which is shown in our previous post. We then look into the visually-similar but sentiment-reversed images by the model with item-as-a-context. Our item-as-a-context CNN gives us another cluster about people, but not in the celebratory mood. What an interesting contrast!

Similarly, we apply the same procedure with a cluster of negative images and would like to see how the reversed sentiment images are going to look like. Can you guess what are positive images portraying small objects on plain surfaces? Ask our context-aware detector and you will have “tasty” answers. Well, probably without the negatives above.




