
The Best Web Scraper for You: A Guide to Understanding Crawlers

In this age where new content is generated on the Web every second, it is only natural that we find ways to harness them. At Preferred.AI, acquiring the ability to harness the wealth of content on the Web has allowed us to build state-of-the-art preference and recommendation libraries to improve the browsing experience for all users. Today, we’d like to share some hints and tips in picking the right open-sourced web crawling framework for your task.
If you are ready, let’s get started!
Introduction
First and foremost, crawlers or crawling frameworks are tools that make web scraping easier and accessible to everyone. These tools bundle essential features that let us do more with less. Each of these frameworks contains a fundamental mechanism that allows us to fetch data from the web – just like a web browser. And unless you are looking to start from scratch, frameworks are a wonder that will help you to save time and effort in solving the crawling task at hand.
Generally, there are two types of crawlers:
- General-purpose crawler
- Focused crawler
Each type of crawler serves a different purpose.. To understand which crawler is right for you, you have to ask yourself:
What is the purpose for my crawl?
General-purpose crawler
If your answer is centered around building a search engine or a full archival of a website, then a general-purpose crawler would be a suitable choice. Typically, a general-purpose crawler will continuously follow every link found on a page and this repeats until there are no more unique links left to crawl. Although some crawlers allow you to restrict the domain or the file type, the process is generally unmanaged and unordered.
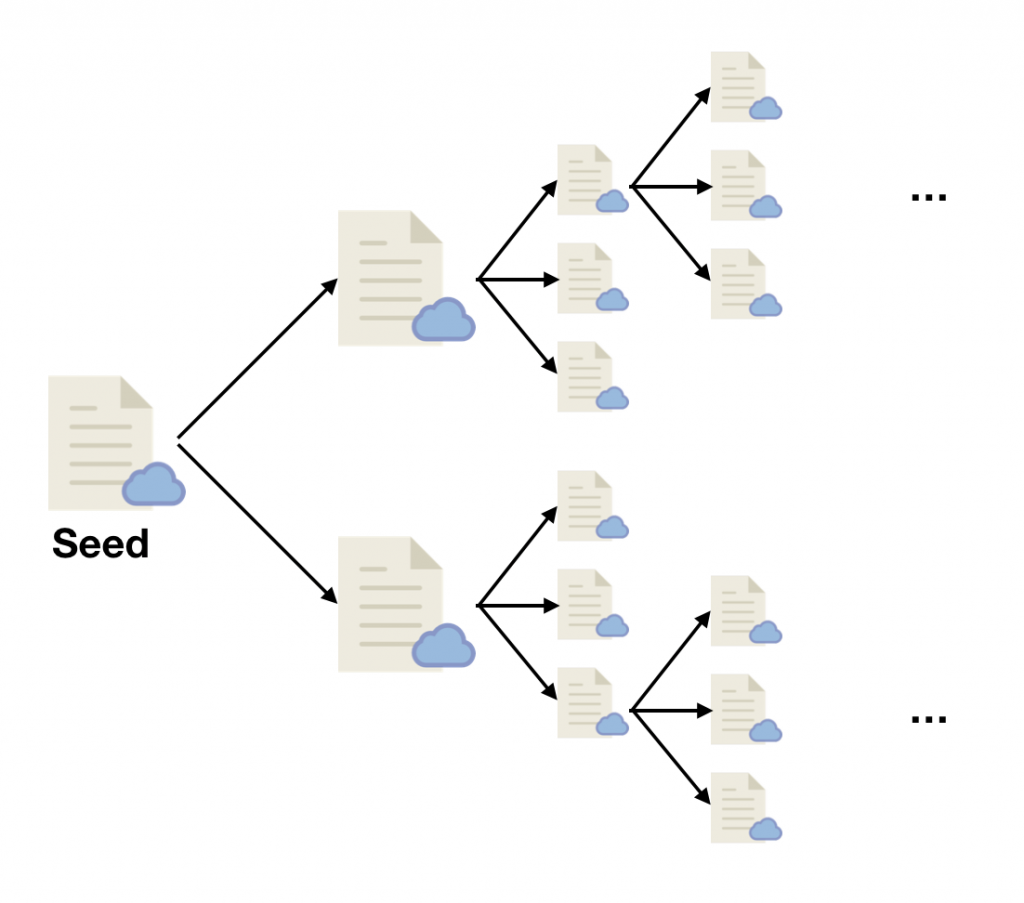
General-purpose crawler also retains raw content (as-is) or have generic parsers that extract some modality of information, for example, a parser that extracts all text on a page. The contents are then stored to the filesystem or a database and are indexed if searchability is required. At the end of the crawl, you will gain a complete but unstructured collection of pages.
Some examples of open-sourced general-purpose crawlers include:
- Apache Nutch – highly extensible, highly scalable web crawler.
- Heritrix – extensible, web-scale, archival-quality web crawler.

Focused crawler
In contrast, if you are looking for a specific set of information for analytics or data mining then you would want to use a focused crawler. Generally, a focused crawler allows you to select and extract the components you wish to retain and dictate the way it is stored.
Here a three benefits of focused crawling:
- collect only what you need resulting in fewer pages visited, less storage consumed, and a faster crawl;
- dictate the way your data is saved, allowing you to structure the data in a manner you can use in your applications;
- total control over the crawling process as elaborated below.
Assume we are crawling an e-commerce site, here are some of the control we may need and an example of what they do:
- use a POST request to submit forms to obtain the price to different shipping locations;
- manipulate cookies to change viewing options such as language or currency types;
- use custom checks such as looking for the word “backdated” to determine if a product has been sold out and reflect it in our database accordingly.
However, a focus crawler is often more challenging to set up as there are more options and control given to the user. If you like to know more, you can check out example of a working crawler here.
Some examples of open-sourced focused crawlers in JAVA and Python include:
- Venom – Your preferred open source focused crawler for the deep web (Java)
- Webmagic – A scalable web crawler framework (Java)
- WebCollector – Simple interfaces for crawling the web (Java)
- pyspider – A powerful spider system (Python)
- Scrapy – A fast high-level screen scraping and web crawling framework (Python)
Choosing the right focus crawler
With tons of options to choose from, how do you choose one that is right? Well, here are some of the factors you should look out for.
Speed
Speed is no doubt at the top of the list as it determines how fast you obtain your results. The speed of the crawler is affected by two aspects, fetching the data from the Web and extracting data from the page. Aside from looking out for crawlers that support multithreading out of the box, you should also look out for crawlers that use asynchronous fetchers (HTTP clients). Unlike synchronous fetchers which support only a single connection per thread, asynchronous fetchers support multiple concurrent connections per threads leading to reduced thread contention and improved speed.
To find out the speed of the different crawlers from the examples above, we set up our test as follows.
Client specification:
- Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz, 3600 Mhz, 4 Core(s), 8 Logical Processor(s)
- 32.0 GB of Installed Physical Memory (RAM)
Server specification:
- 4 x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz, 2200 Mhz, 6 Core(s), 12 Logical Processor(s)
- 256.0 GB Installed Physical Memory (RAM)
- NGINX web server
To keep the comparison fair, we set the maximum number of connections to eight (8) which is also the number of logical processors in the client. As such, all synchronous crawlers are permitted to use a maximum of eight threads and all asynchronous crawler are permitted to use a maximum of eight connections. In addition, we made sure to set each crawler to have no delay between requests.
We passed 10,000 URLs to each crawler and averaged the results for two tests.
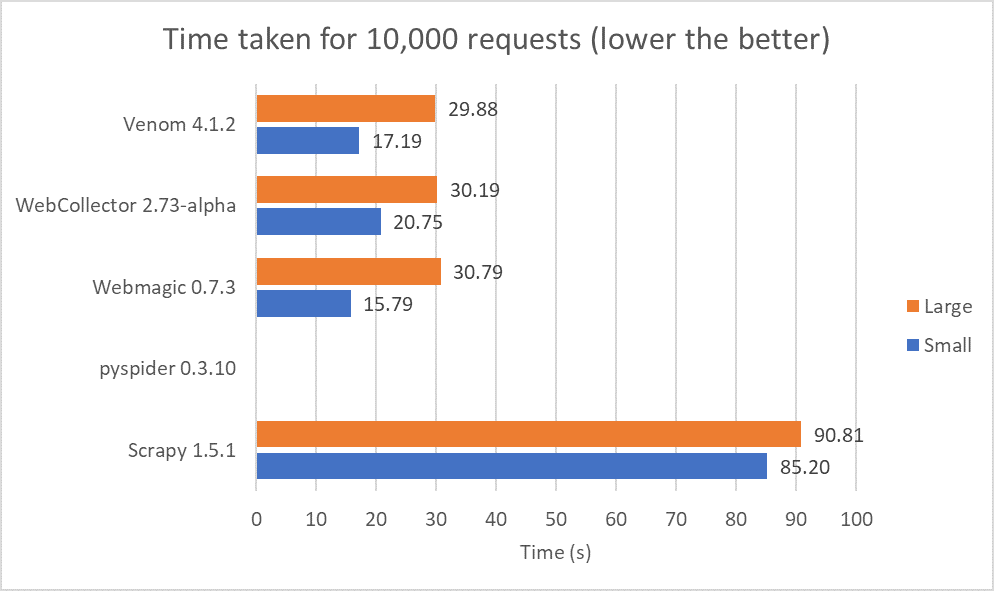
Unfortunately, pyspider took too long to run and we decided to abandon the test at the five-minute mark. We can see that crawlers written in JAVA seem to perform well and are much faster than those in Python when ran directly from the command line. Much of this speed difference is due to GIL, which restricts a Python instance to a single processor. Luckily, some developers of Python crawlers provide an additional crawling server to make full use of a multiprocessor system, but this requires some set-up which might be tedious for newer users.
To show that asynchronous fetchers can have a speed improvement given the same amount of threads, we chose to pit Webmagic (top synchronous crawler tested) against Venom (top asynchronous crawler tested). We doubled the allowed maximum connections while keeping the number of threads constant. This test was ran twice and had their averages taken.
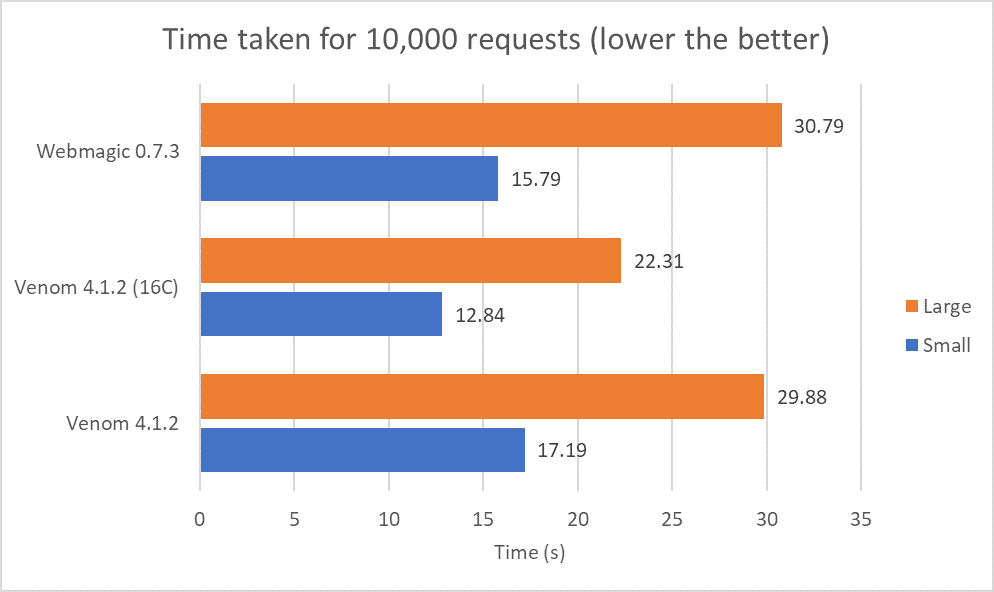
Time taken for 10,000 requests with 8 threads but different number of max connections
Memory footprint
RAM usages is an important factor in determining the number of crawlers you can run, and it’s definitely one issue that will bug your systems administrator. Although there’s not much you can do to make sure all memory leaks are plugged in the framework, there are some choices you can make to reduce memory footprint.
Once again, you can opt for frameworks which use asynchronous fetchers as they are more memory efficient due to fewer threads used. Adjusting the number of concurrent connection will also affect memory usage, so make sure you consult your systems administrator before embarking on a large crawling task.
Other features
Most of the crawler frameworks are feature packed, however, these are some of the basic features that are essential.
- Proxy support
- Validation and retries if error code received (404, 500, .etc) or fails custom checks
- Multi-database support
This list is by no means exhaustive, I will continue to add features as I find them to be useful. There are tons of crawling frameworks out there and with these factors to keep in mind, I’m sure you will be able to find one that suits your need.



{kind=link}