
Introduction to CSVPL
Here in Preferred.AI, much of our work involves processing and manipulating data. We regularly find ourselves wanting to explore a given dataset quickly and simply, and CSVPL (CSV Processing Language) allows us to do just that. CSVPL is a Java library for simple and extensible CSV (comma-separated values) file processing and manipulation, and in this post, we will be introducing CSVPL, as well as demonstrating its usage and features.
Why CSVPL?
One of our favorite ways to collect data from the web is with our very own Venom web crawler, and we often store the output in a CSV file, as shown below.
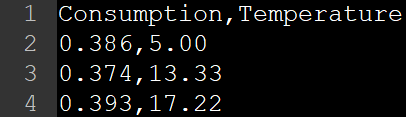
Now that we have collected all this data, how do we make use of it? Typically, we use large datasets for the training of a mathematical model, which calculates an output through a learnt combination of its input variables. Such models, once trained, can then used to predict results from arbitrary inputs. Before we begin to construct the model, however, we typically find it useful to conduct an initial data exploration. This step involves understanding the relations between various variables in the dataset, which then allows us to create models that better fit the dataset. CSVPL simplifies such data exploration tasks, allowing us to conduct them quickly through a simple API.
Using CSVPL
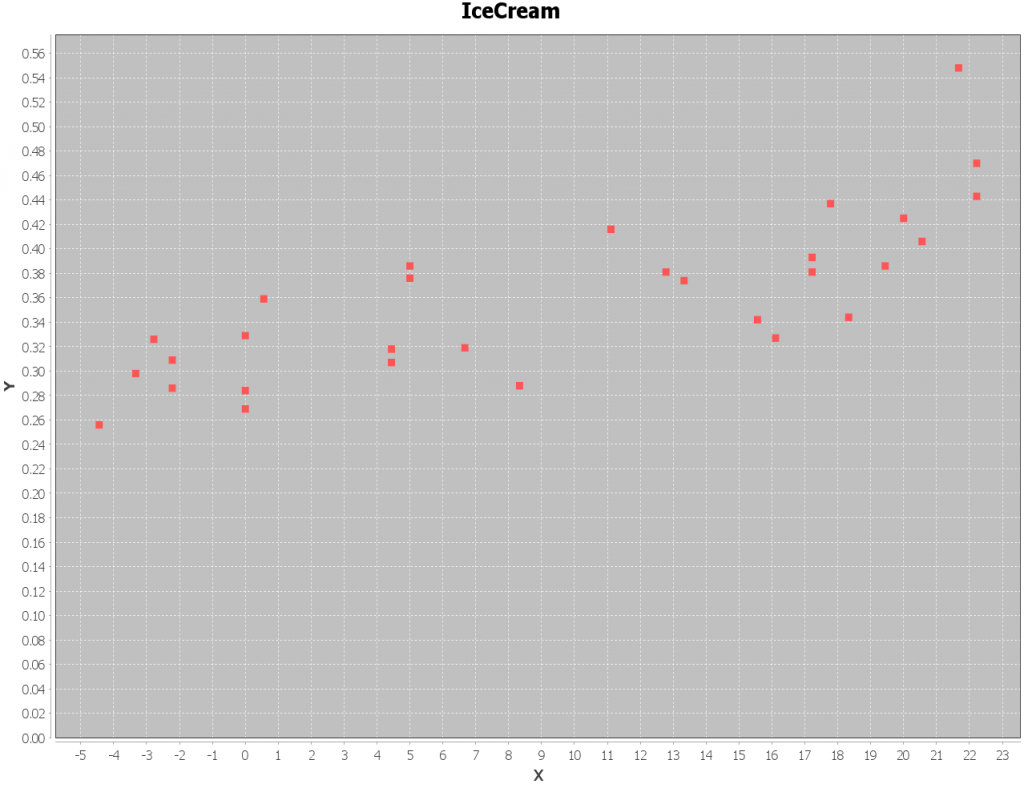
How simple is CSVPL to use? Definitely simpler than it is to pronounce1, that’s for sure! Suppose we want to visualize the relation between the Consumption and Temperature columns in icecream.csv. All it takes is a single line of code:
Shell.run(PlotData.class, "--input data/icecream.csv --name IceCream");
This command runs the PlotData class with two arguments, input and name. The input argument is the location of the CSV file to be visualised, while the name argument is used for the title of the output plot.
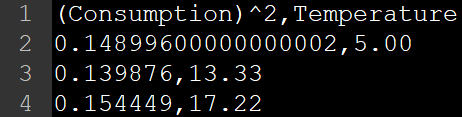
Suppose we now want to plot the square of Consumption against Temperature. First, we can get the square of Consumption with the following line of code:
Shell.run(AddX2.class, "--input data/icecream.csv --output data/icecream_2.csv --column 0");
This creates a new output file at the specified location, and opening icecream_2.csv, we can see that a new column ((Consumption)^2) has been added to the end of each row:

Next, we remove the Consumption column, and swap the Temperature and (Consumption)^2 columns:
Shell.run(RemoveColumn.class, "--input data/icecream_2.csv --output data/icecream_3.csv --column 0");
Shell.run(SwapColumns.class, "--input data/icecream_3.csv --output data/icecream_4.csv --column-x 0 --column-y 1");
Opening up icecream_4.csv, we see that our data has been transformed into the proper format for PlotData
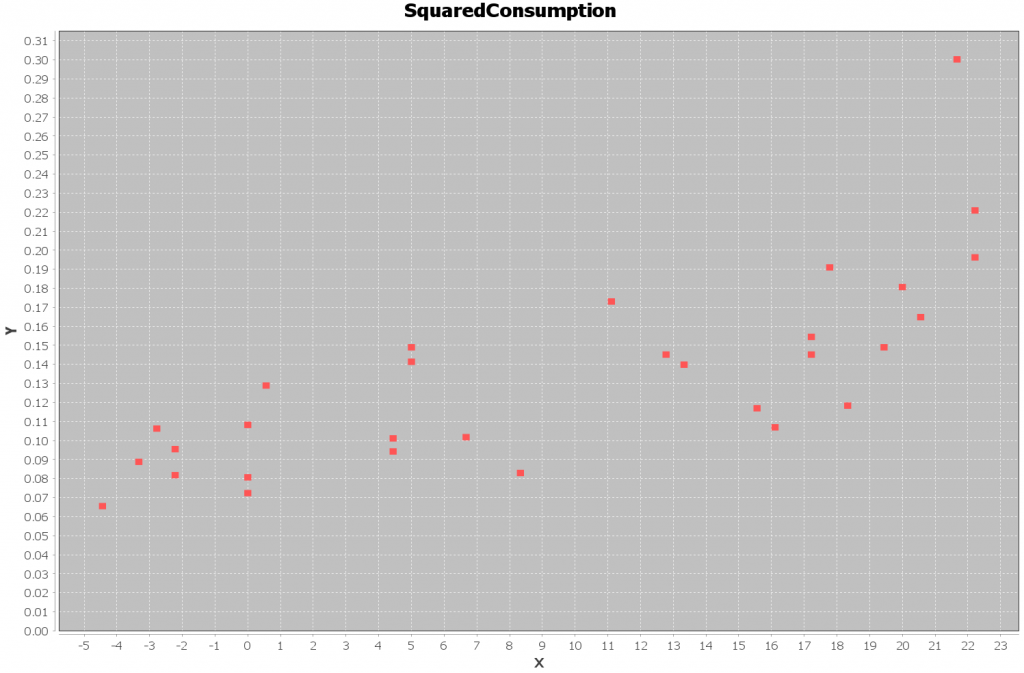
We can then visualize icecream_4.csv the same way we did before:
Shell.run(PlotData.class, "-i data/icecream_4.csv -n SquaredConsumption");
If everything goes to plan, you should get the following plot:
Extending CSVPL
CSVPL is also built to be extensible, allowing you to add your own custom processing elements! To do so, just edit dummy.java and place the modified java file into the pe folder. There are two parts to the file to edit, corresponding to the modifications required for the headers and the data.
For headers, we typically add a new column at the end of the existing headers. However, if you intend to to modify the value of an existing header, consider moving the header to the end instead.
Data is received as an ArrayList, with each String object representing one row of data. First, we can get a column value by record.get(column_index). Next, we process the data, after which we add it to end of the record with record.add(new_value). Again, if we are modifying the value of an existing header, remember to remove the old value with record.remove(column)! Lastly, we do printer.printRecord(record) to write the processed row to the output file.
Next Steps
After reading this post, you should now know what CSVPL is and how to use it. We hope that CSVPL is able to provide you with a simple and extensible alternative to packages such as SciPy or Scikit-Learn for data exploration.
Interested to try CSVPL for yourself? Clone (and star!) the CSVPL github repository, where you can try the exercises or just use it to explore some sample datasets. Also, don’t forget to send a pull requests if you create a new Processing Element!
[1] Here at Preferred.AI, we pronounce it /si ɛs vi pi ɛl/



