Why maximum likelihood-based training may lead to the generation of unrealistic samples
Why maximum likelihood-based training may lead to the generation of unrealistic samples
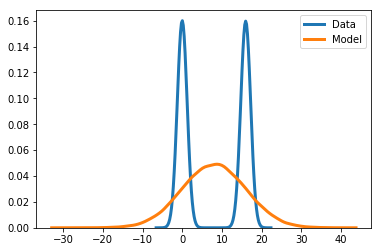
Generative models specify procedures allowing us to produce data samples, e.g., images, texts, user preferences, etc. These models are central to unsupervised learning, and popular examples include mixture models [1], mixed membership models such as latent Dirichlet allocation [2] and probabilistic matrix factorization [3], variational autoencoders [4], just to name a few. In this post, we discuss the behavior of maximum likelihood-based training, and we show that this procedure may result in models that can produce unrealistic samples, i.e., which are unlikely under the real data distribution.
Setting
We are typically given a set of observations (e.g., images) x_1, \ldots, x_n , and our goal is to come up with a model that would allow us to generate samples that look like our observations. To this end, a common approach consists in positing a parametric model p_\theta(x) and estimating it from our data. A predominant framework in this context is maximum likelihood (ML) estimation. The idea is to find the value of the parameters \theta that are most likely to have generated the observations, by maximizing the log-likelihood function: